Hola Mundo Apache Nifi
Category : Noticias
Apache Nifi es una herramienta ETL desarrollada en java. Es open source y es interesante porque es una herramienta web útil para pequeños procesos ETL.

Sirve para automatizar de manera eficiente y visual de los flujos de datos e incluso se permite insertar código java.
Instalación de Apache Nifi
Podemos ir a la página de descargas de Apache Nifi y descargar la última versión disponible. En el momento de escribir este artículo la versión 1.19.1
Una vez descargado y descomprimido, vamos a hacer un pequeño proceso de carga de datos.
Vamos a cargar los datos de covid de Cataluña por municipio y sexo que ofrece el portal de datos abiertos de la generalitat que se pueden descargar de esta url: https://analisi.transparenciacatalunya.cat/resource/jj6z-iyrp.json
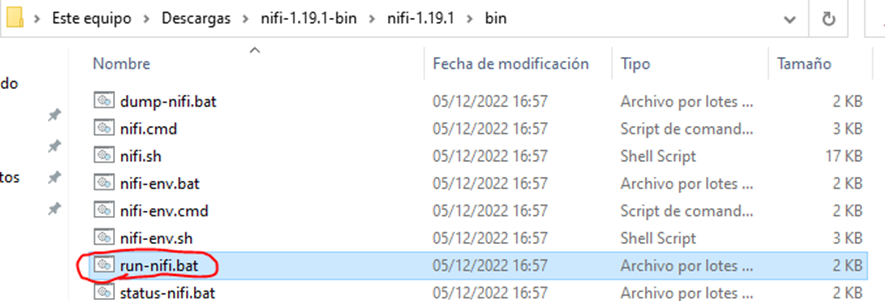
Ejecutar apache nifi.
Para ejecutar apache nifi es necesario acceder a la carpeta “bin” de nuestra instalación y ejecutar el archivo run-nifi.bat
Encontrar el usuario y contraseña para el login.
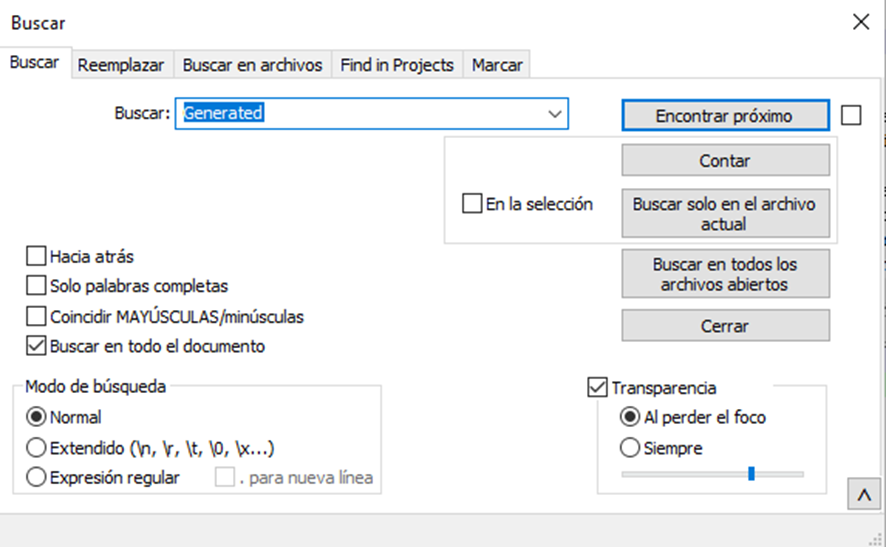
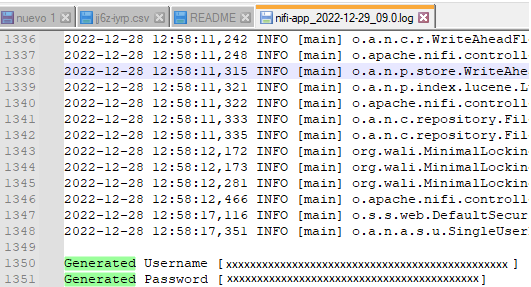
Para encontrar el usuario y contraseña que está generado por defecto es necesario ir a la carpeta “logs” y abrir el archivo nifi-app.log en caso de que no sea la primera vez que inicie el apache nifi el archivo que hay que abrir será el siguiente “nifi-app_YYYY_MM_DD.0.log”. Y buscar generated. Si eres un usuario de windows lo puedes hacer con la función buscar de notepad++. Si eres un usuario de linux siemplemente haz grep Generated nifi-app.log
Entonces tendremos el Username Y el Password disponible para poder hacer copy-paste.
Ahora ya podemos abrir un navegador e ir a https://localhost:8443/nifi que es la url por defecto.
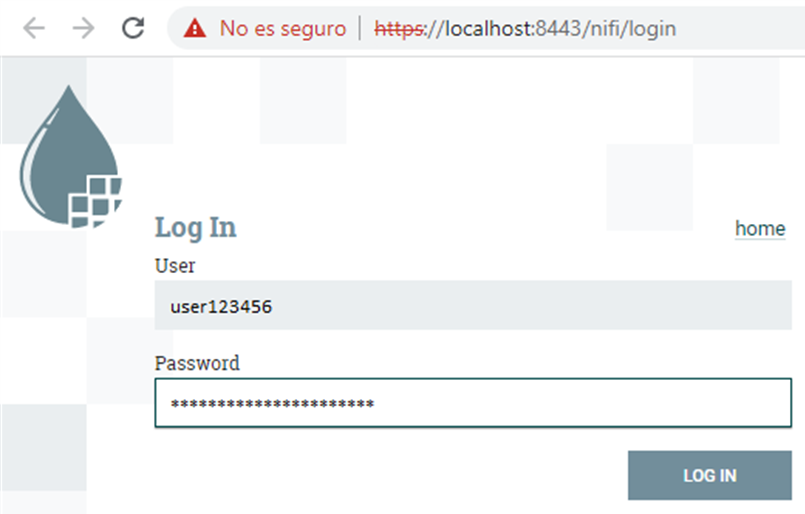
Metemos los datos en el login y ya está listo para usar.
Esta pantalla muestra el entorno donde estamos trabajando a continuación explicare que es cada cosa y para qué sirve:

Esta es la barra donde en principio solo crearemos los procesadores que es el primero a la izquierda:

Para añadir un procesador es necesario arrastrar-lo a la pantalla.
Esta es el mapa de navegación de nuestro entorno, es útil por si queremos ajustar la medida de la pantalla e incluso moverla.
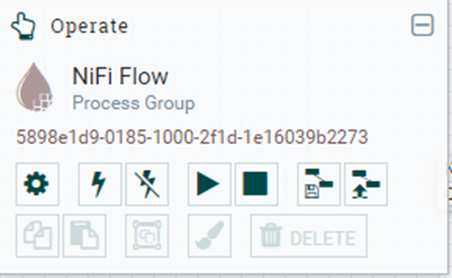
Esto es la ventana para realizar varias acciones que tengan que ver con el funcionamiento del flujo de datos que en resumen permite poner en marcha, parar, activar y desactivar el flujo de datos o el procesador seleccionado. El símbolo del engranaje permite acceder a la lista de servicios que se quiere configurar si no hay ningún procesador seleccionado en caso contrario sirve para configurar el procesador seleccionado.
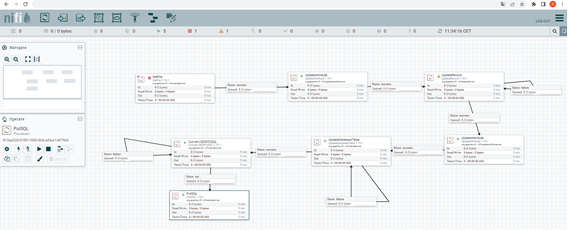
Hola Mundo: Cargar un csv en una tabla
Qué es un flujo de datos, un procesador y que es un servicio
Flujo de datos:
Es la ruta que ha fijado el desarrollador en el programa/entorno de datos para realizar el ETL deseado que consiste en extraer, transformar y sobrescribir los datos en una base de datos. En esa ruta se usan unos procesadores y servicios configurados para su funcionamiento deseado, en este caso para extraer datos de un csv, transformar los datos a postgreSQL, crear la tabla en la base de datos y meter los datos en la tabla creada.
Procesador:
Es un módulo del flujo de datos que realiza una función en concreto, por ejemplo el procesador GETFILE se encarga de extraer en este caso el archivo csv que se necesita.
Servicio:
Los servicios son funciones que están integradas en ciertos procesadores para realizar funciones específicas que no se pueden realizar dentro del procesador y que requieren una configuración aparte para funcionar.
Por ejemplo el procesador llamado UpdateRecord que es el encargado de transformar los datos del CSV al JSON no puede por si mismo realizar esas funciones, necesitan funciones que funcionan aparte del procesador que son dos servicios: uno llamador CSVReader y el otro llamado JsonRecordWriter. Para acceder a dicha configuracion hay que clicar a la flecha que nos llevara a la lista de servicios.

Clicamos en el engranaje:
Explicación de todos los pasos que hemos hecho y por qué los hemos hecho.
Extraer los datos
Para empezar necesitamos datos que extraer en este caso hemos de tener el archivo en nuestra carpeta local (no he podido realizarlo a través del enlace web), una vez hecho esto debemos añadir un procesador llamado GetFile.
Para configurar el procesador hay dos opciones: hacer dos clics en el procesador o hacer un clic en el procesador y posteriormente clicar en el engranaje de la ventana de operación que está debajo de la ventana de navegación.
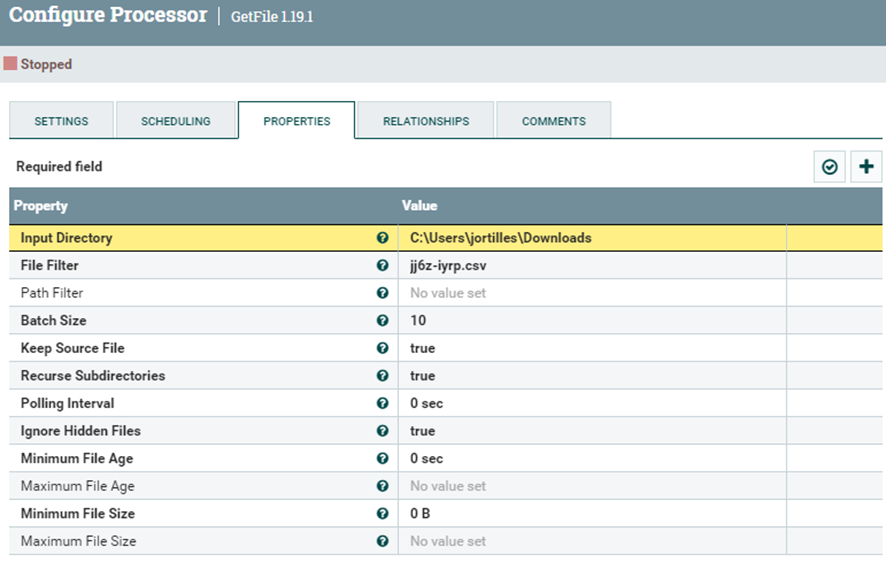
Una vez dentro debemos clicar a la pestaña de propiedades para configurar.
Entonces aparecerá la pantalla que sale arriba.
Las propiedades importantes son Input Directory, File Filter, y Keep Source Filter que hacen las siguientes cosas:
- Input Directory:
Es la carpeta local desde donde debemos extraer los datos en este caso la carpeta de descargas.
- File Filter
Aquí debemos poner el nombre exacto del archivo concreto.
- Keep Source Filter
Aquí debemos de decir si queremos conservar el archivo que debemos procesar o no. Se recomienda tenerlo en true para poder hacer pruebas de forma más dinámica, es decir sin tener que descargar el archivo por cada vez algo que salga mal.
Una vez tenemos estas tres cosas configuradas podremos extraer un archivo en específico situado en una carpeta especifica.
Crear un Schema name
Debemos crear un schema name porque se nos pedirán más adelante, para realizarlo es necesario crear un procesador llamado UpdateAttribute.
Después entramos en la configuración para definir la variable Schema.name

Para crear la variable es necesario añadir propiedad.
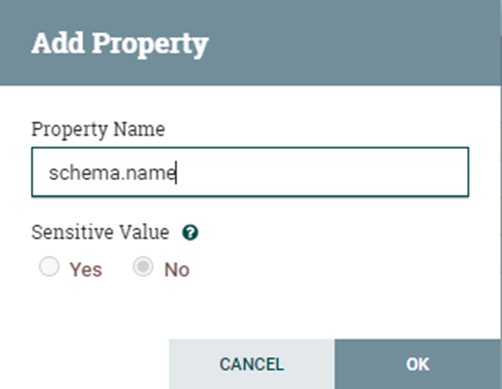
Escribimos el nombre de la propiedad.
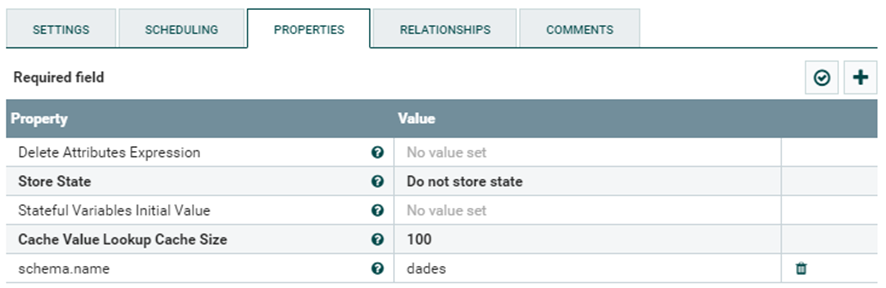
Si a continuación escribimos dades en el “Value” de la propiedad que hemos creado saldrá el mismo resultado que en la imagen superior.
Para acabar debemos relacionar el GetFile con este procesador para continuar con la ruta que cumplirá el objetivo final aunque no realice ningún cambio en el archivo que estamos transportando.
Para hacerlo se debe poner el cursor encima del procesador para que aparezca el siguiente símbolo:
El siguiente paso es clicar i mantener pulsado para luego arrastrar el cursor hacia el siguiente procesador:

Luego aparecerá esta ventana para confirmar la conexión entre estos dos procesadores en caso de que el anterior procesador tenga un resultado positivo con su función.
Simplemente es clicar en “Add” y ya está.

Convertir el archivo .csv a .json
El primer paso debe ser crear el procesador UpdateRecord ya que es el encargado de leer el archivo CSV y sobrescribirlo en JSON.
Entramos en configuración:
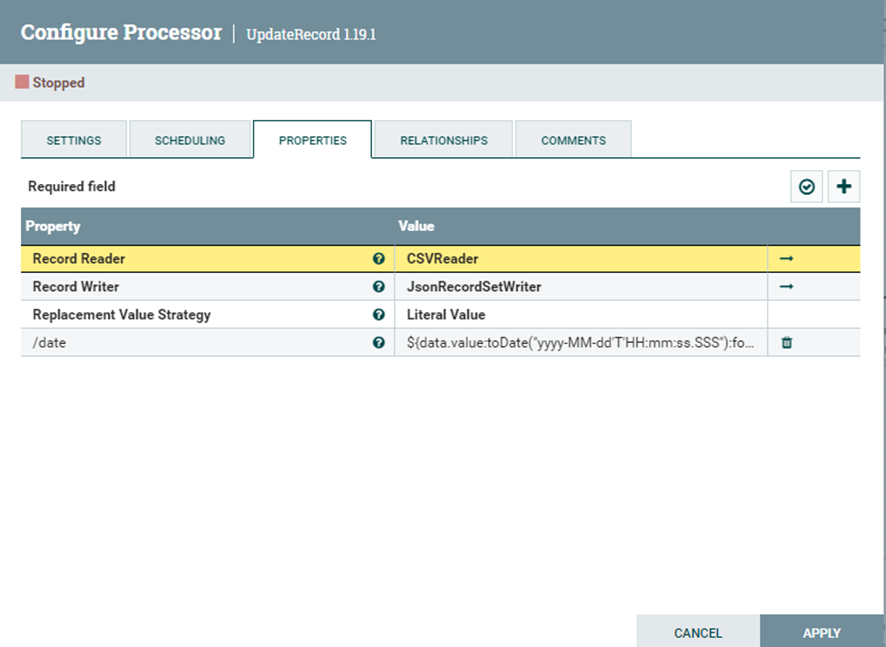
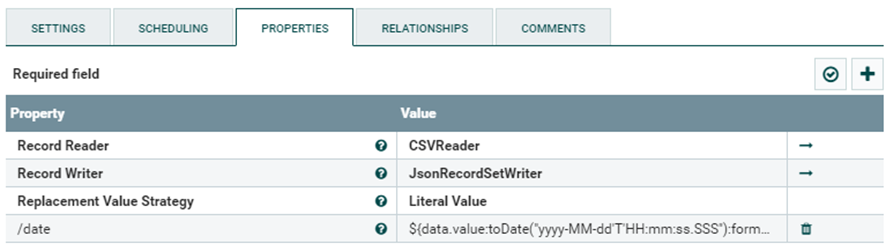
Esta imagen muestra como debería estar configurado el procesador. Por supuesto ignorando la propiedad /date ya que no es funcional.
Para seleccionar el Record Reader y el Record Writer deseados debemos de hacerlo de la siguiente forma:
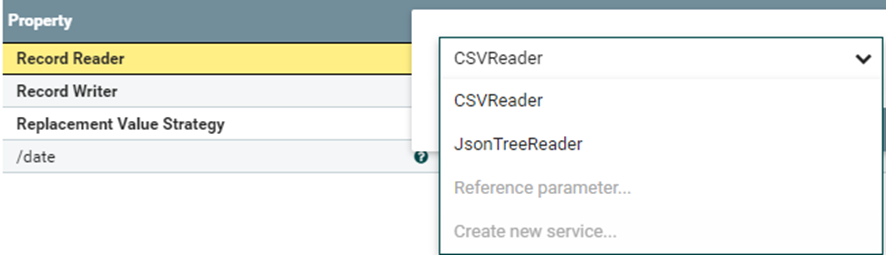
En este caso ya tenemos el CSVReader ya que lo tenemos configurado. Pero para el que lo está configurado se debe ir a Create new service para crear el servicio de lectura de CSV.
Si clicamos en “Create new service…” aparecerá la siguiente ventana:
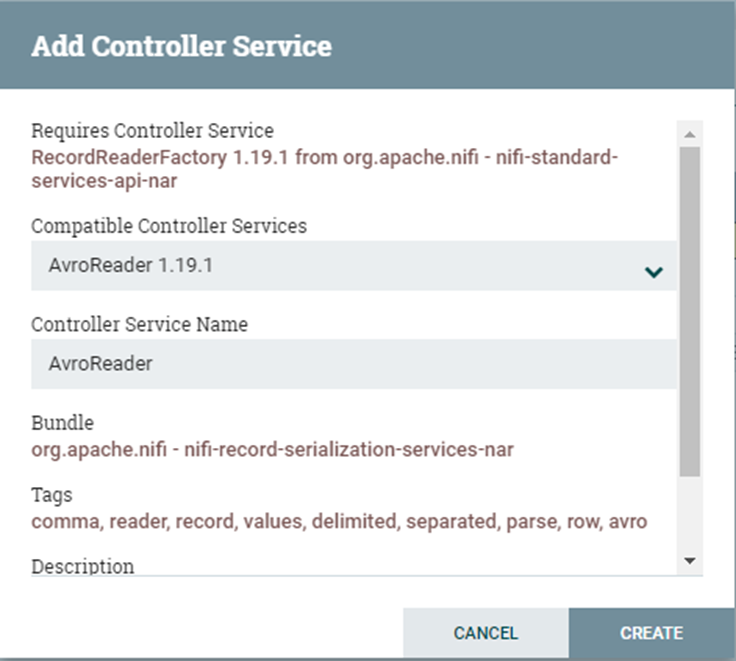
Aquí debemos buscar el servicio deseado en el desplegable donde pone “Compatible Controller Services” y encontrar el servicio “CSVReader” para luego seleccionarlo y posteriormente clicar el botón “CREATE”.
En “Record Writer”
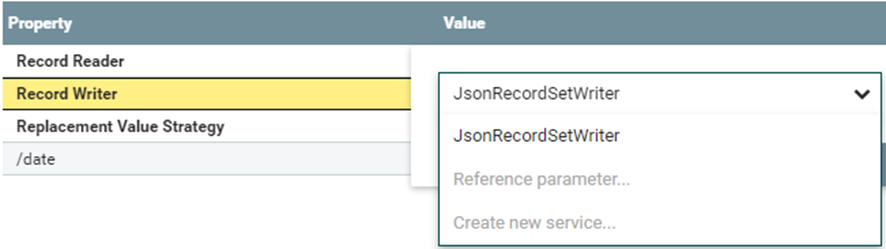
Repite el mismo proceso pero Sustituyendo el “CSVReader” por “JsonRecordSetWriter”.
Ahora clica una flecha y le llevará a esta pantalla:
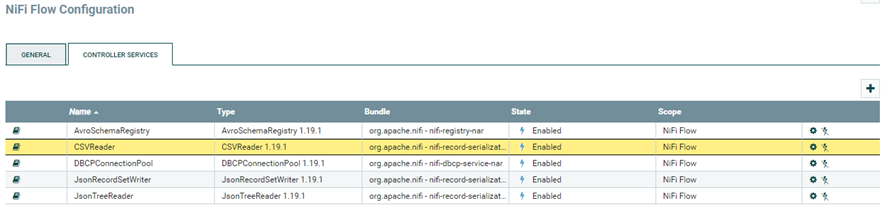
Como habrá notado se ha creado un servicio llamado “AvroSchemaRegistry”. Clica en el engranaje para abrir su configuración.
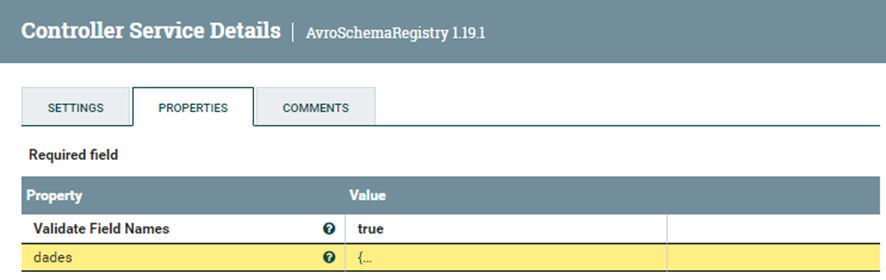
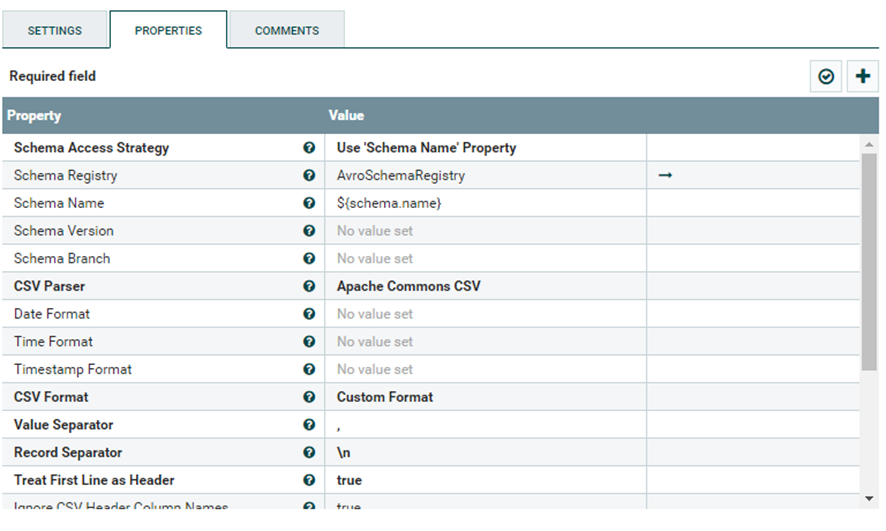
Tanto el “CSVReader” y el “JsonRecordSetWriter” necesitan saber con antelación que tipo de datos van a leer y como se llaman por tanto se tiene que crear un molde dentro de este servicio llamado “AvroSchemaRegistry”.
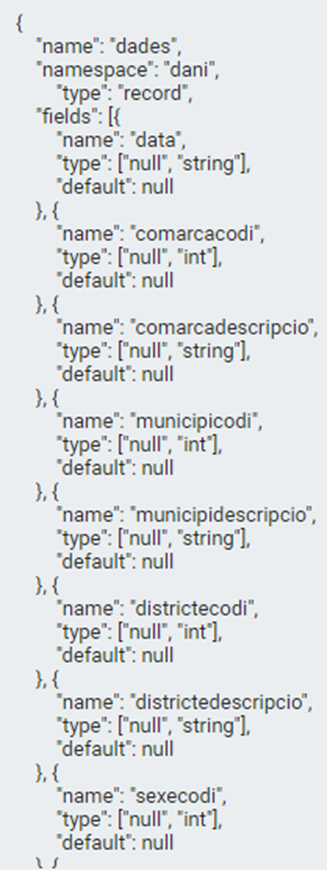
Este el molde en este caso concreto para leer los datos del csv que hemos puesto en el GetFile. NOTA IMPORTANTE: El orden de las variables tiene que ser exactamente el mismo que el del archivo CSV porque si no dará error.
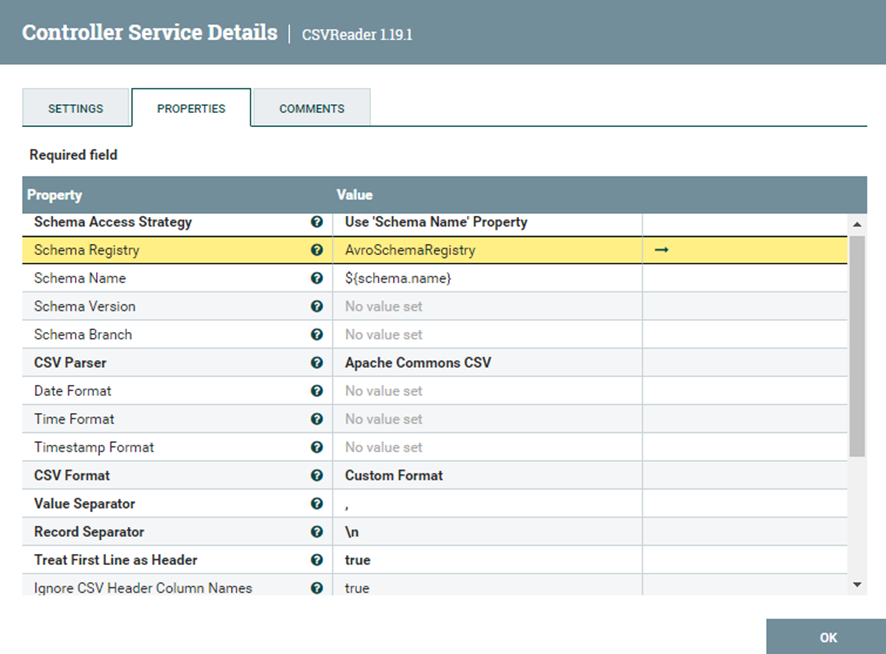
En el CSVReader son importantes estas propiedades:
Schema Access Strategy: Es la forma de acceso a los datos en este caso es a través del nombre de la variable schema.name.
Schema Registry: A través de qué servicio registrará los datos en este caso el “AvroSchemaRegistry”.
Schema Name: El nombre de la variable schema.name
Treat First Line as Header: Como el nombre indica trata la primera línea como columnas, se indica true porque es verdad que en la primera línea del CSV contiene los nombres de las columnas.
Ignore CSV Header Column Names: Como el nombre indica ignora el nombre de las columnas, se marca true porque no necesitamos registrar el nombre de las columnas ya que en el propio “AvroSchemaRegistry” se ha definido un molde de una tabla de datos y a continuación el servicio “JsonRecordSetWriter” se encargara de transformar un JSON con los datos del CSV a través del molde.
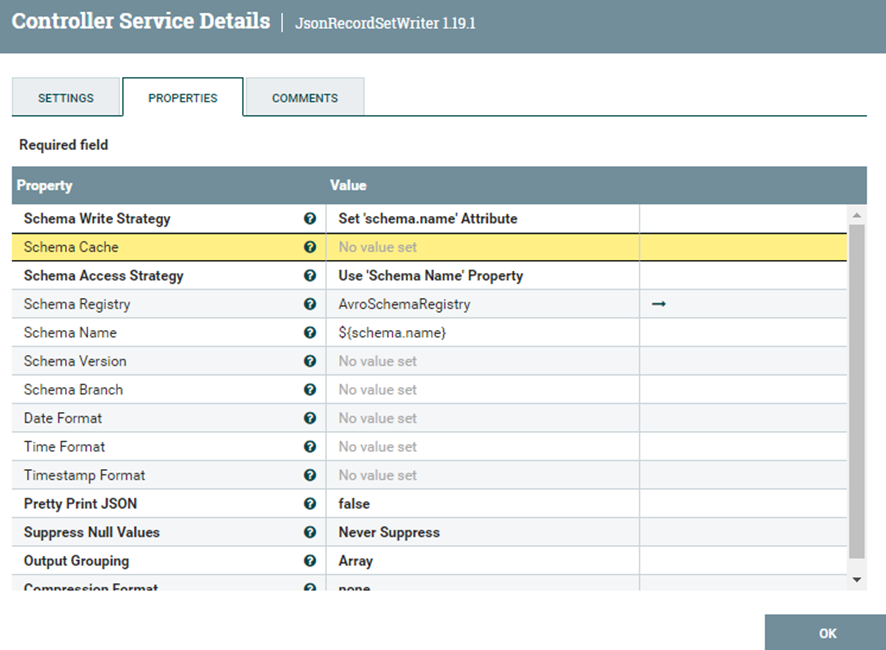
En el “JsonRecordSetWriter” simplemente es poner esta configuración en específico.
Si la operación tiene éxito podemos pasar al siguiente paso, en caso contrario es importante interpretar correctamente el error ya que el error más común que se puede encontrar es en la sintaxis del modelo del “AvroSchemaRegistry”, comprueba el orden de las columnas es exactamente las mismas que en el CSV, comprueba que la sintaxis es correcta y por último que el nombre y el tipo de datos de las columnas sean exactamente los mismos que los que están definidos en el archivo CSV.
A continuación se crea otro UpdateAttribute para actualizar el nombre del archivo convertido.
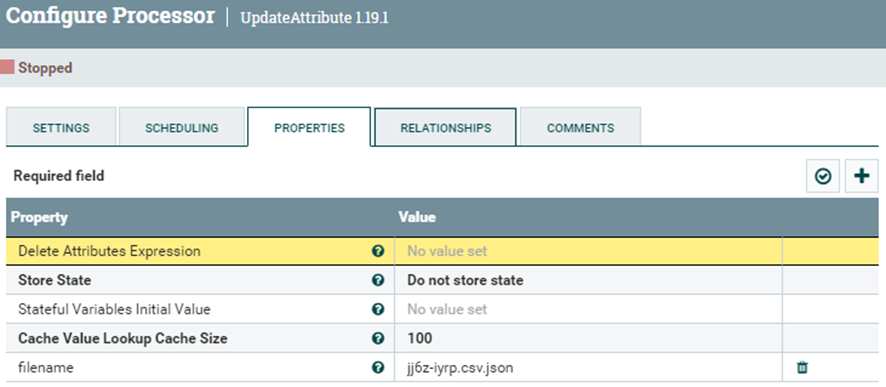
Para realizarlo es necesario crear una propiedad llamada “filename” y escribir el nombre que se llamara el archivo una vez pase este procesador.
Creamos el procesador “UpdateDatabaseTable” ya que ahora que tenemos el archivo convertido en json, ahora es necesario actualizar nuestra base de datos ya que no hemos creado la tabla que contendrá los datos que queremos añadir.
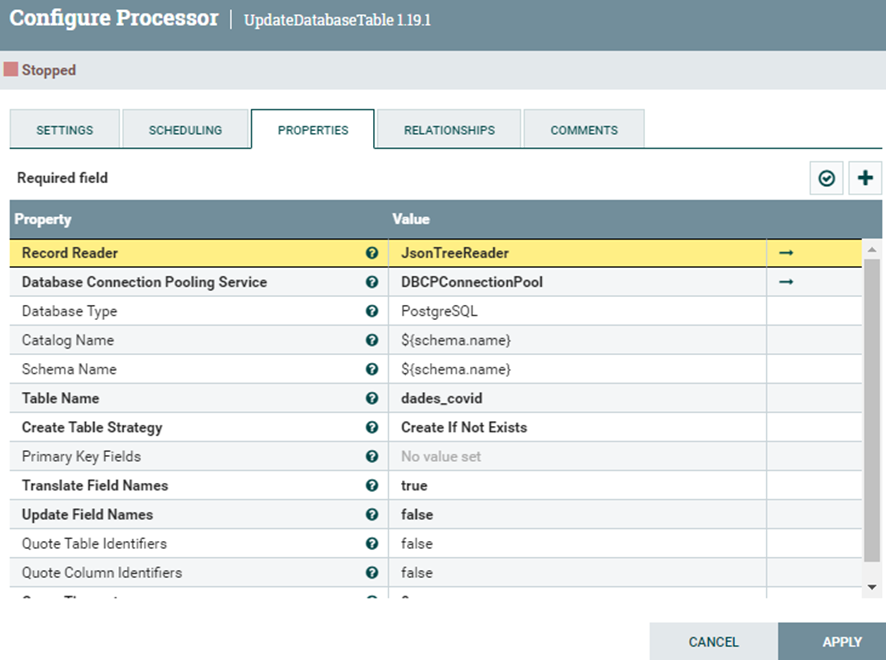
Al entrar en configuración es necesario 2 servicios:
- Record Reader
Se encargara de leer en formato JSON la estructura de la base de datos con el Servicio llamado “JsonTreeReader”. En principio no requiere realizar una configuración ya que se presupone que la configuración por defecto debería funcionar en nuestro caso. Si no es el caso, la captura de abajo debería servir.
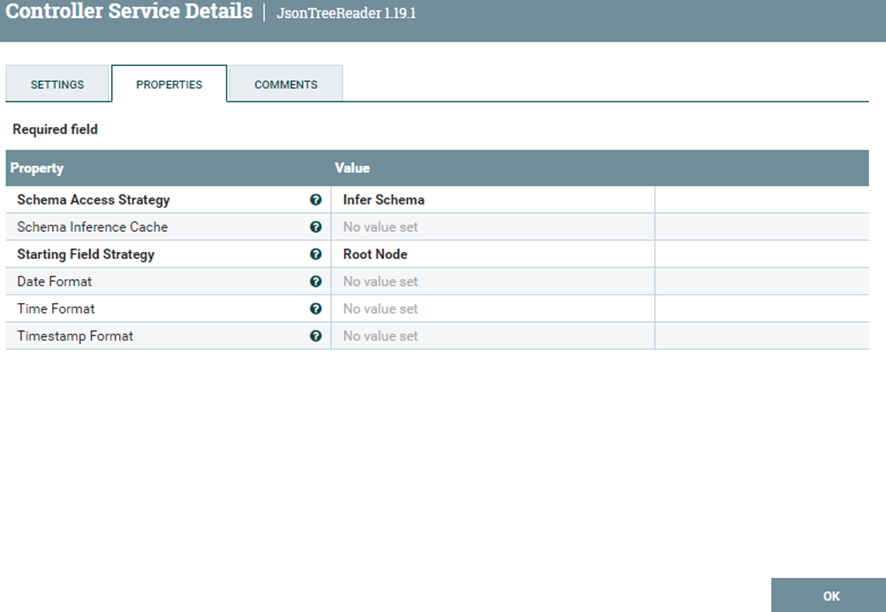
- Database Connection Pooling Service
Se encargará de conectarse a la base de datos a través del servicio llamado “DBCPConnectionPool” que requiere estos pasos previos antes de hablar de la configuración:
- Descargar el postgresql jdbc
El “postgresql jdbc” es un controlador que permite a los programas java conectarse a las bases de datos tipo postrgesql.
Para descargarlo simplemente entra a esta URL y descarga una versión compatible con nifi que perfectamente puede ser la versión java 8.
- Preparar el controlador para ser usado
Se necesita meter el controlador en una carpeta llamada “jbdc” dentro de la carpeta de nifi.
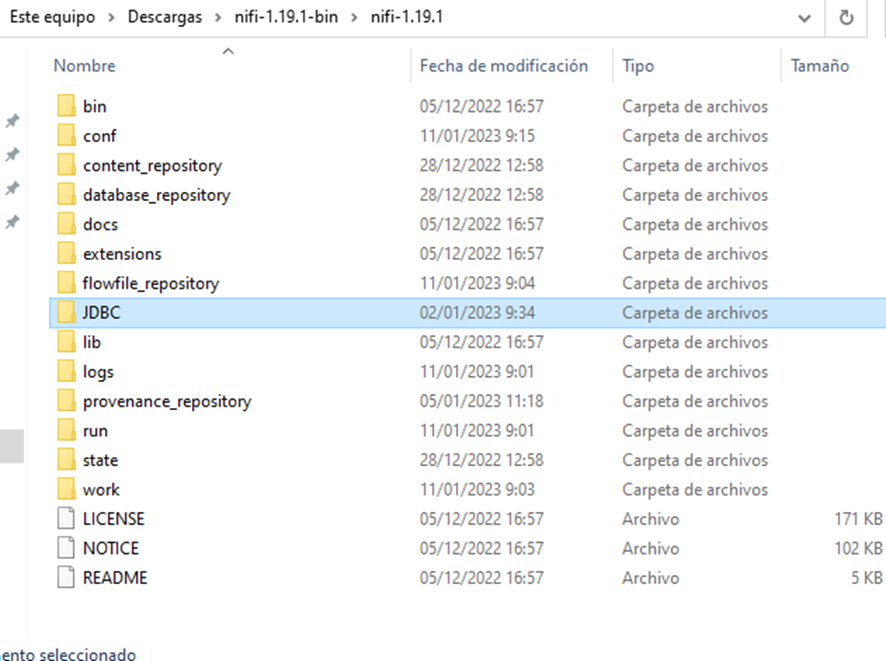
Esta es la carpeta que tenemos que crear, exactamente con este nombre y en mayúsculas
Dentro de esta carpeta metemos el archivo que hemos descargado

Vamos a la lista de servicios que tenemos instalado y creamos un nuevo servicio llamado “DBCPConnectionPool” y luego entramos en su configuracion.
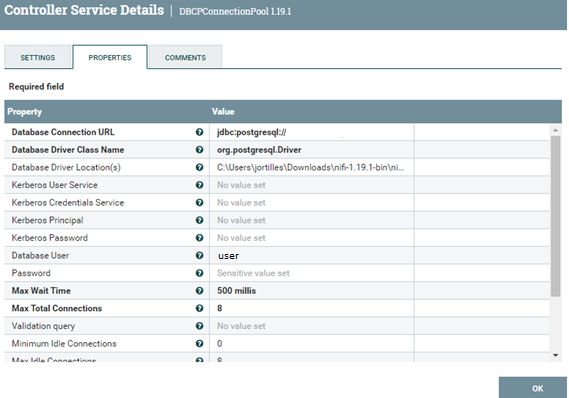
Como definir estas variables:
- Database Connection URL
Es la url de la base de datos en la que se trabajará pero, antes de poner la url de la base de datos es necesario añadir al comienzo esta url: jdbc:postgresql://
Y justo después la dirección url del servidor que quedaría más o menos así:
jdbc:postgresql://url.servidor.com:0000/name
- Database Driver Class Name
En nuestro caso que es una base de datos postgreSQL se debe poner exactamente esto: org.postgresql.Driver que sirve para llamar al controlador para que realice la función deseada que es que sea capaz de leer y editar la base de datos.
- Database Driver Location(s)
Aquí se debe poner tanto la dirección de la carpeta donde esta el postgresql-42.5.1.jar como el nombre del postgresql-42.5.1.jar, para que funcione correctamente.
- Database User
El usuario de la base de datos no del nifi.
- Password
La contraseña de la base de datos no del nifi.
Una vez configurado los servicios correctamente y se ha comprobado que no hay ningún error al validar, es hora de configurar el procesador “UpdateDatabaseTable”.
Insertar datos
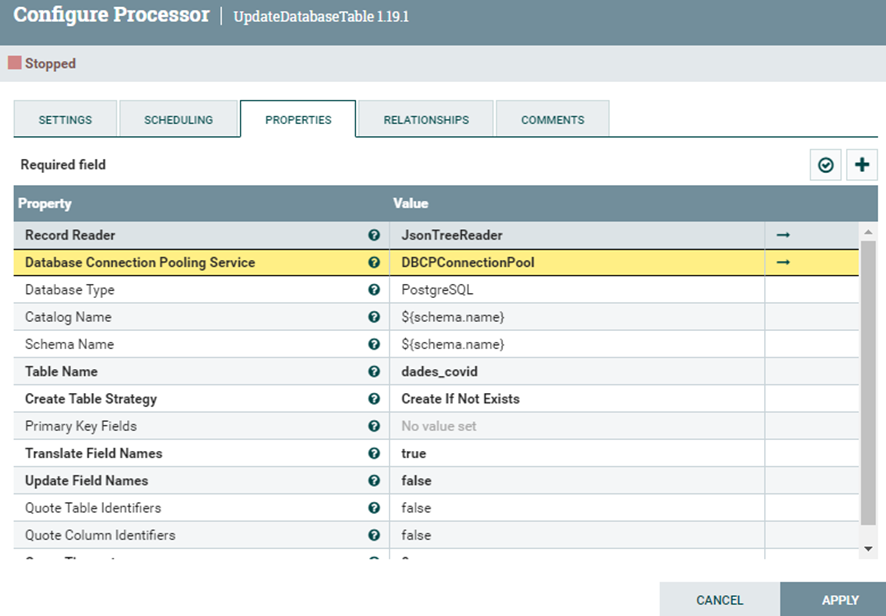
Es necesario modifcar estas propiedades:
- Database Type
Aquí pondremos el tipo de base de datos que vamos a crear, en este caso sería con PostreSQL.
- Catalog Name
Es poner el nombre del schema nada más.
- Schema Name
Es poner el nombre del schema nada más.
- Table Name
Ponemos el nombre de la tabla que queremos crear.
- Create Table Strategy
Aquí definimos la estrategia de creación de la tabla, nuestro objetivo es que cree la base de datos si no existe, para eso debemos definirlo en “Create If Not Exists”.
Si se ha configurado los dos servicios y este procesador correctamente, debería comprobar que se ha creado la tabla en la base de datos.
Con este procesador vamos a convertir el JSON en SQL y a mas mas generara una sintaxis para crear esos mismos datos en nuestra base de datos.
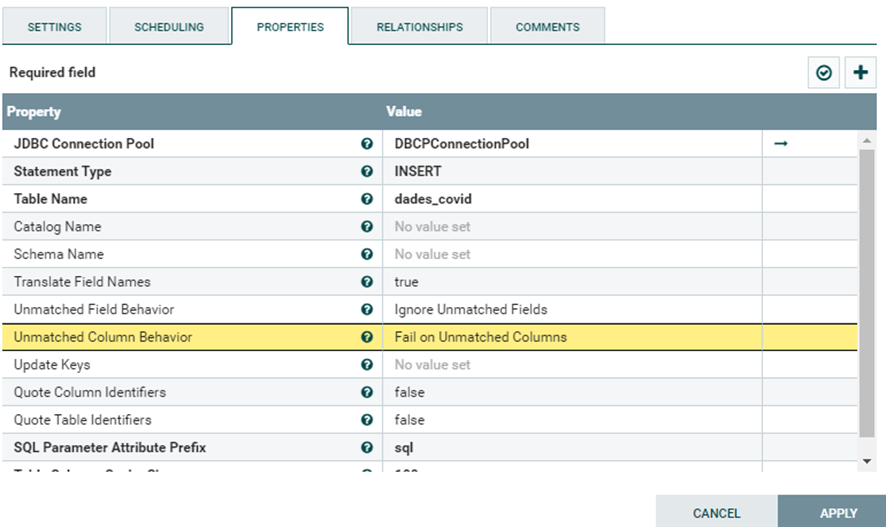
En la configuración solo es relevante dos propiedades:
- Statement Type
Qué tipo de operación queremos realizar una vez convirtamos el JSON a SQL. En este caso como queremos insertar los datos debemos seleccionar la opción “INSERT”.
- Table Name
El nombre de la tabla creada en nuestra base de datos
Este procesador como su nombre indica inserta el código sql generado en el anterior procesador a la base de datos, no se necesita en principio ninguna configuración en sus propiedades, pero si en sus relaciones ya que al ser la última operación del flujo de datos es necesario auto terminar.
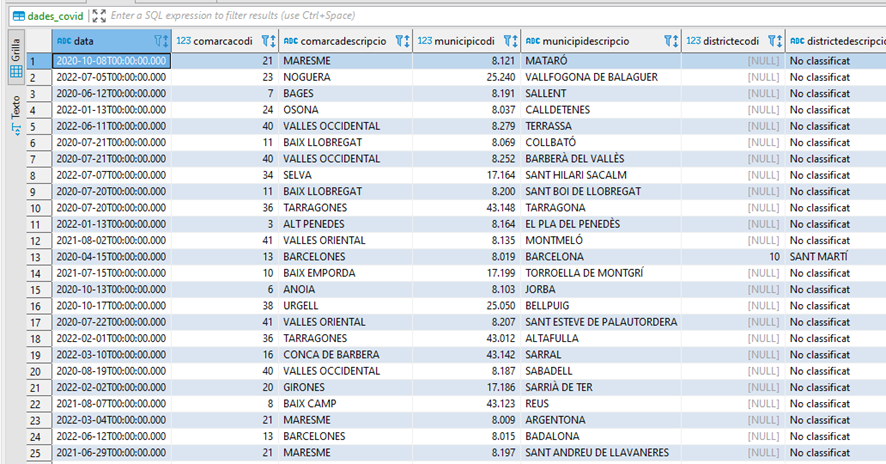
Si todo va bien se debería comprobar en la tabla creada si se han añadido los datos.
El aspecto final de nuestro proceso es este: