TensorFlow.js
Category : Noticias
Tensorflow.js es una de las principales librerías para el desarrollo y entrenamiento de modelos de machine learning. Nosotros usaremos su implementación en JavaScript. Esto nos facilitará hacer un ejemplo sencillo y funcional. TensorFlow nos permite hacer clasificaciones: Según los datos que tengo, predigo que este cliente compara o no comprara. Pero también podemos hacer regresiones. Según los datos que tengo, predigo que este cliente debería gastarse X importe.
En este ejemplo nuestro objetivo es construir un modelo sencillo de red neuronal para resolver un problema de clasificación binaria ( compra o no compra ) y presentar las herramientas que ofrece la librería para diseñar y probar el modelo.
En los problemas de clasificación el objetivo es que nuestro modelo sea capaz de, dada una entrada, predecir si la salida será de tipo A (Compra) o B ( No Compra). En éste caso se trata de una problema de clasificación binaria puesto que sólo hay dos clases de salida (A-Compra o B-No compra), pero puede extenderse a más de dos clases.
Generalmente se introduce como primer ejemplo de éste tipo la classificación de imágenes, en los que la entrada es una imagen (codificada) y la salida nos dice si se trata de un número u otro, o qué letra es, que animal, etc. Podemos encontrar numerosos ejemplos puesto que es un caso paradigmático. En la página de tensorflowjs hay un tutorial completo de clasificación de números en base a imágenes muy recomendable si ya se tiene algo de experiéncia con los modelos.
Éste tipo de problema requiere lidiar con las imágenes, los pixeles y su representación binaria, además es necesária un tipo de red (CNN, convolutional neural network) que de por si añade bastante complejidad al modelo y sus capas. Por eso hemos buscado un ejemplo en el que los datos sean más sencillos y fáciles de tratar, de forma que podamos centrarnos en ver los elementos más básicos de un modelo sin que la complejidad añadida de las imágenes interfiera en el proceso.
¿Qué necesitamos?
-Un set de datos
-Un modelo (en éste caso una red neuronal sequencial con tres capas)
-Entrenar el modelo
-Probar el modelo
Configuración
En nuestro caso optaremos por la solución mas sencilla, basada en el siguiente esquema de archivos:
- index.html
- script.js
En el archivo html nos basta con poner los enlaces a la cdn de tensorflow js y a nuestro script:
<!DOCTYPE html> <html> <head> <meta charset="utf-8"> <meta http-equiv="X-UA-Compatible" content="IE=edge"> <meta name="viewport" content="width=device-width, initial-scale=1.0"> <title>TensorFlow.js Tutorial</title> <!-- Import TensorFlow.js --> <script src="https://cdn.jsdelivr.net/npm/@tensorflow/tfjs@1.0.0/dist/tf.min.js"></script> <!-- Import tfjs-vis --> <script src="https://cdn.jsdelivr.net/npm/@tensorflow/tfjs-vis@1.0.2/dist/tfjs-vis.umd.min.js"></script> <!-- Import the main script file --> <script src="script.js" ></script> </head> <body> </body>
También hay un enlace a la cdn de tfjs-vis, una librería complementaria de tensorflowjs que nos servirá para visualizar las estadísticas de nuestro modelo.
Con esto estamos a punto para utilizar la librería en nuestro script.
Los datos
Disponer de un set de datos válido es fundamental para llegar al objetivo. En nuestro caso hemos diseñado un set de datos hecho a medida para asegurarnos de que todo funciona como esperamos. El punto de partida es el siguiente: tenemos un conjunto de clientes y disponemos de tres variables para cada uno: grupo de edad (ge), estudios y género. Por otro lado queremos averiguar que probabilidad hay de que un cliente que se ha interesado en nuestro producto termine comprándolo.
Es decir, disponemos de tres variables de entrada (grupo de edad, estudios y género) y una de salida (compra o no compra).
La idea es que la red pueda aproximar la función f(edad,genero, estudios) = y con suficiente precisión como para predecir con un 100% de acierto la salida ‘y’ dada una entrada (edad,genero, estudios).
Codificación de las variables
Grupo de edad: tenemos tres grupos (1: 18-25 años, 2: 26-35 años, 3: > 35años)
Género: H-M
Estudios: tres grupos (1: sin estudios, 2: estudios básicos, 3:estudios superiores)
El problema que tenemos con éstos datos es que són datos categóricos, no numéricos. Para solucionar éste problema usaremos el one hot encoding que consiste en lo siguiente:
Se trata de codificar los valores de la variable de manera que cada posible valor es una nueva variable. Por ejemplo, si el género es hombre o mujer (H, M), lo que haremos será convertir esto en:
H = [1, 0], M = [0, 1]
La idea es que ahora hay dos variables (H y M) y para cada entrada (cliente) cada una tomará el valor 1 o 0. Haremos lo mismo con las otras dos variables, pero en éste caso como tienen tres valores tomarán la forma: [0, 0, 1] para el primer valor, [0, 1, 0] para el segundo y [1, 0, 0] par el tercero.
De ésta forma un cliente Mujer, en el grupo de edad 1 y con nivel de estudios 1 tendría el siguiente aspecto para el sistema:
[0, 1, 0, 0, 1, 0, 0, 1] ([Genero, edad, estudios])
De forma que hemos codificado las 3 variables en 8 que toman el valor 0 o 1.
Para la salida hacemos lo mismo y ahora en vez de una única variable tenemos dos:
[compra, noCompra] -> [1, 0] ó [0, 1].
Una vez tenemos codificadas las variables lo que haremos es generar un set de datos aleatório, es decir un conjunto fictício de clientes con las variables que hemos definido.
Para que nuestro modelo sea capaz de predecir si una determinada entrada (x) convierte o no (y) tiene que existir una relación entre las variables y las salidas. Nosotros hemos generado éstas relaciones estableciendo normas arbitrárias del tipo:
- si el grupo de edad es 1 y el nivel de estudios es 1, y = compra.
- Si el nivel de estudios es 2 y el genero es H, y = noCompra.
La idea es partir de un caso muy sencillo con unas normas fijas y ver si nuestra red es capaz de “descubrir” las reglas que hemos establecido. En un caso real la gracia es que ni conocemos estas reglas ni en la mayoría de los casos existe una relación tan evidente entre las variables de entrada y salida, así que de lo que se trata es de que la red pueda descubrir si existe tal relación de forma que sea posible predecir una determinada salida.
Hay algunas limitaciones que tenemos que tener en cuenta:
El volumen de datos de cada clase de salida (compra o noCompra) tiene que ser similar. Una cosa que nos pasó en el proceso de diseño de la red es que si nuestros datos tenían un 80% de y=compra y un 20% de y=noCompra la respuesta de la red era predecir que el cliente siempre compraba y con eso conseguía un 80% de aciertos.
Por otro lado hay que tener en cuenta que es necesario un volumen de datos mínimo para que la red pueda realizar el proceso de aprendizaje, nosotros generamos 10.000 clientes y con esto ha sido suficiente, pero trabajamos con un caso en el que las relaciones las hemos fijado nosotros y son muy claras. Segun el caso puede ser necesarioun volumen mayor de datos. Por ello el análisis de BigData ha tomado la importancia que tiene actualmente, los volúmenes de datos ingentes que generamos permiten realizar procesos de inferencia de información que no serían posibles con volúmenes mas reducidos.
Las normas són las siguientes (no hay lógica alguna mas que intentar que los valores para y = compra [1, 0] e y = noCompra [0, 1] estén equilibrados.
if (edad === 2 && genero === 0) {
ys[i] = [1, 0];
} else if(edad == 2 && estudios === 1) {
ys[i] = [1, 0];
} else if(estudios === 0 && genero === 1) {
ys[i]= [1, 0];
}else if(estudios === 2 && genero === 1 && edad === 0){
ys[i]= [1, 0];
}else{
ys[i]= [0, 1];
}
La representación gráfica de nuestra función:
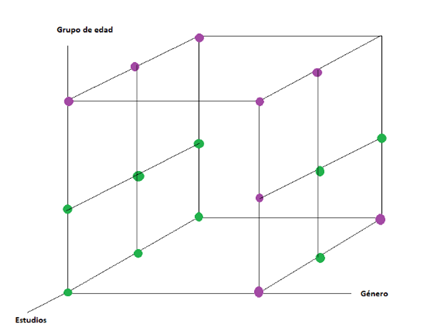
Es una función discreta, es decir hay un número limitado de posibles entradas y salidas. Esto se debe a que trabajamos con categorias y cada categoria puede tomar un número limitado de valores. Cada combinación de entradas (edad, genero y estudios) da una única salida (verde o morado) que se corresponden con las ys (compra, noCompra). La idea es que nuestro modelo sea capaz de aproxmar ésta función. Dada su simplicidad esperamos que el modelo sea capaz de llegar al 100% de precisión.
Una vez generados los datos y establecidas las relaciones es hora de desarrollar el modelo: nuestra red neuronal.
Tensores
Un tensor es una generalización de los conceptos de escalar, vector y matriz. No entraremos en detalle en ello, lo que necesitamos saber es que la unidad de trabajo básica para los datos en tensorflow són los tensores. Todos los datos que le pasamos tiene que convertirse a tensores, sobre los que luego se aplican transformaciones, operaciones, etc. Pero de todo esto se encarga tensorflow.
En el nivel en el que trabajamos lo que necesitamos saber es como convertir los datos en tensores y como trabajar con ellos a nivel básico, lo veremos más adelante.
El modelo
Un modelo consta de la siguientes partes:
- Capas (layers), cada capa tiene un determinado número de neuronas
- Funciones de activación. A cada capa se le asigna una función de activación.
- Función de pérdida. Se encarga de calcular el error en la predicción.
- Algoritmo que se aplica para corregir el error calculado por la función de pérdida.
Después de algunas pruebas nosotros hemos llegado al siguiente modelo. Lo hemos encapsulado dentro de una función que lo devuelve, tal como se propone en los tutoriales de tensorflow.js:
function getModel() {
const model = tf.sequential();
model.add(tf.layers.dense({
inputShape: [INPUT_LENGTH],
units: 3,
activation: 'relu',
}));
model.add(tf.layers.dense({
units: 1,
activation: 'sigmoid',
}));
const NUM_OUTPUT_CLASSES = 2;
model.add(tf.layers.dense({
units: NUM_OUTPUT_CLASSES,
kernelInitializer: 'varianceScaling',
activation: 'softmax'
}));
const optimizer = tf.train.adam();
model.compile({
optimizer: optimizer,
loss: 'categoricalCrossentropy',
metrics: ['accuracy'],
});
return model;
}
Aquí definimos un modelo de tipo secuencial, los hay de mas tipos pero pqueda fuera del alcance de éste post entrar en detalle en éste tema.
Añadimos una capa de tipo dense, el inputShape es la forma de nuestra entrada, que como hemos visto consta de 8 unos y ceros para cada cliente, que representan la codificación de las tres variables de entrada.
Units són las neuronas que tiene y activation es la función de activación, en éste caso la función relu.
Añadimos una siguiente capa con una sola neurona y otra más con dos, para las dos salidas. El modelo devuelve la probabilidad de que para una entrada la salida sea y = [1, 0] ó y = [0, 1].
Finalmente añadimos el optimizador y la función de pérdida y compilamos el modelo, que es retornado por la función para que podamos trabajar con él. Aquí hay muchísimo que aprender y como hemos comentado no es nuestra inención entrar en todos los detalles de configuración de la red.
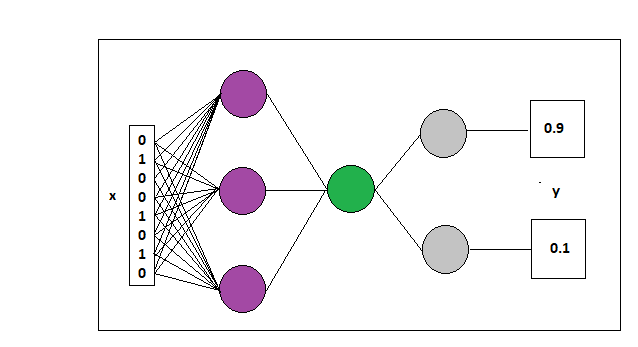
El modelo es el siguiente, dónde tenemos la entrada x que es un vector con 8 posiciones que se correponden con la codificación de las 3 variables y una salida ‘y’, que són dos valores: la probabilidad de que la salida sea ‘compra’ o ‘noCompra’ ([1, 0] ó [0,1]).
Entrenando el modelo
Una vez disponemos de un modelo y un conjunto de datos el siguiente paso es entrenar el modelo con los datos para que sea capaz de realizar predicciones.
En nuestro caso la función que genera los datos devuelve un array de arrays con las x y otro con las correspondientes y, de forma que tenemos:
Xs = [[0,1,0,0,1,0,0,1],[1, 0, 1, 0, 0, 0, 1, 0], … etc];
Ys = [[0, 1],[1, 0],…etc]
Para el entrenamiento diseñamos una función que recibe como parámetros el modelo, las ‘xs’ y las ‘ys’:
async function train(xs, ys, model) {
//separamos los datos en entrenamiento y test
let trainXS = xs.slice(0, TRAINIG_DATA);
let trainYS = ys.slice(0, TRAINIG_DATA);
let testXS = xs.slice(TRAINIG_DATA, TOTAL_DATA);
let testYS = ys.slice(TRAINIG_DATA, TOTAL_DATA);
//Convertimos en tensores
const [tXs, tYs] = tf.tidy(() => {
return [
tf.tensor2d(trainXS, [TRAINIG_DATA, INPUT_LENGTH]),
tf.tensor2d(trainYS, [TRAINIG_DATA, 2])
];
});
const [testXs, testYs] = tf.tidy(() => {
return [
tf.tensor2d(testXS, [TEST_DATA, INPUT_LENGTH]),
tf.tensor2d(testYS, [TEST_DATA, 2])
];
});
//Definimos las métricas que mostraremos en pantalla
const metrics = ['loss', 'val_loss', 'acc', 'val_acc'];
const container = {
name: 'Model Training', styles: { height: '1000px' }
};
const fitCallbacks = await tfvis.show.fitCallbacks(container, metrics);
//Función de entrenamiento del modelo
const a = await model.fit(tXs, tYs, {
batchSize: BATCH_SIZE,
validationData: [testXs, testYs],
epochs: EPOCHS,
shuffle: true,
callbacks: fitCallbacks
});
}
Lo primero que hacemos es separar los datos en dos sets: entrenamiento y test. Esto es necesario para hacer lo siguiente: en cada iteración el modelo ajusta los parámetros según los datos de entrenamiento y luego los testea con los datos de test, de forma que podamos monitorizar la evolución del sistema comparando lo aprendido con datos nuevos que el sistema no ha visto.
Luego transformamos los datos en tensores. La función tidy se encarga de la gestión de la memoria (cada tensor que se genera tiene que ser eliminado cuando deja de usarse puesto que sino el uso de memoria se resiente significativamente ).
Nosotros usamos tensores 2d puesto que tenemos entradas y salidas en forma de array de una dimensión y tenemos tantos arrays como entradas. Y eso es lo que le pasamos al tensor:
(data_en _forma_de_array, [cantidad_de_data, tamaño_de_los_datos]);
En nuestro caso el tamaño de los datos es 8 para las x y 2 para las y, como hemos visto en la parte en la que codificamos las variables.
Finalmente usamos algunas de las funciones de la librería de soporte para las visualizaciones tfjs-vis y entrenamos el modelo.
Las métricas, el container y los fitCallbacks són parte de la visualización. Por otro lado a la función model.fit() le pasamos los tensores que hemos creado para las xs y las ys (tXs, tYs) y un objecto de configuración en el que tenemos:
Épocas: número de veces que el modelo ‘ve’ todos los datos de entrenamiento. En nuestro caso las tenemos fijadas en una constante a 10.
batchSize: tamaño de los fragmentos en los que se dividen los datos para cada época. Fijado en una constante a 80.
Para cada época se pasan fragmentos de datos del tamaño batchSize hasta que el modelo ha visto todos los datos y para los que se ajustan los parámetros de la red. Sin entrar en detalles, en general es recomendable tener un batch size pequeño pero suficientemente significativo para minimizar el número de épocas y evitar el overfiting.
Por último el parámetro shuffle a true desordena los datos puesto que en algunos casos la red puede inferir información del orden, pero luego los datos de test o los datos sobre los que se intenta predecir pueden no tener éste orden, con lo que el modelo habría aprendido una relación que en realidad no existe o que es casual.
Finalmente tenemos una función run() que ejecuta en secuencia las funciones que hemos definido:
async function run() {
let data = generateData();
let xs = data[0];
let ys = data[1];
const model = getModel();
tfvis.show.modelSummary({ name: 'Model Architecture' }, model);
await train(xs, ys, model);
}
document.addEventListener('DOMContentLoaded', run);
Generamos los datos y el modelo, que se pasan como parámetros a la función train. Como hemos añadido elementos de visualización de la librería tfjs-vis, si cargamos nuestra página index.html en el navegador veremos que empiezan a visualizarse distintos datos:
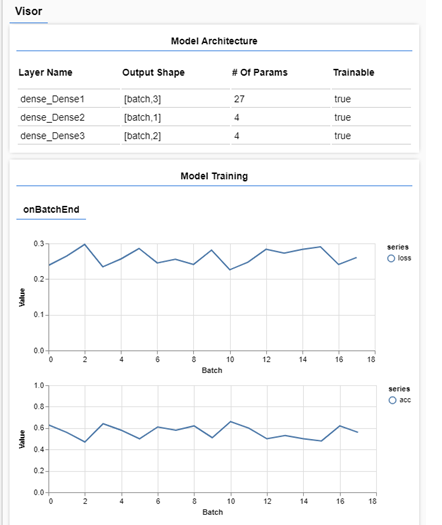
Se muestra un resumen del modelo (capas, forma de la salida y parámetros por capa) y también vemos como el modelo entrena en tiempo real.
En un caso ideal la salida de la función de pérdida deberia de ser cada vez mas pequeña y la precisión (accuracy) debería de ser cada vez mayor. Si nuestra red funciona correctamente debería de ser capaz de reconocer los patrones que hemos introducido en los datos de entrada y salida y debería dar un 100% de precisión (asumiendo que hemos diseñado un modelo de datos con unas relaciones bastante simples del tipo si a ^ b ->e, si b ^c ^d -> f, etc.
Cuando finaliza el proceso obtenemos ésto:
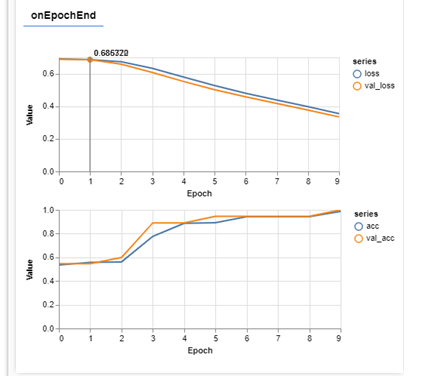
Nuestro modelo ha podido inferir las normas que hemos establecido hasta conseguir un 100% de precisión en sus predicciones, lo cual nos produce muchísima satisfacción siendo nuestro primer intento y a pesar de ser un caso muy sencillo.
Evaluar el modelo
Una vez entrenado el modelo podemos evaluarlo, para ello definimos tres funciones, una para las predicciones y otras dos para visualizar el proceso.
function doPrediction(model, xs, ys) {
let PREDICT_SIZE = 1000;
let testXS = xs.slice(TOTAL_DATA - PREDICT_SIZE, TOTAL_DATA);
let testYS = ys.slice(TOTAL_DATA - PREDICT_SIZE, TOTAL_DATA);
const testxs = tf.tensor2d(testXS, [PREDICT_SIZE, INPUT_LENGTH]);
const labels = tf.tensor2d(testYS, [PREDICT_SIZE, 2]).argMax([-1]);
const preds = model.predict(testxs).argMax([-1]);
testxs.dispose();
return [preds, labels];
}
async function showAccuracy(model, xs, ys) {
let classNames = ['Yes', 'No'];
const [preds, labels] = doPrediction(model, xs, ys);
const classAccuracy = await tfvis.metrics.perClassAccuracy(labels, preds);
const container = { name: 'Accuracy', tab: 'Evaluation' };
tfvis.show.perClassAccuracy(container, classAccuracy, classNames);
labels.dispose(); //con ésto eliminamos de la memoria el tensor 'labels'.
}
async function showConfusion(model, xs, ys) {
let classNames = ['Yes', 'No'];
const [preds, labels] = doPrediction(model, xs, ys);
const confusionMatrix = await tfvis.metrics.confusionMatrix(labels, preds);
const container = { name: 'Confusion Matrix', tab: 'Evaluation' };
tfvis.render.confusionMatrix(
container, { values: confusionMatrix, tickLabels : classNames });
labels.dispose();
}
La función model.predict() (llamada dentro de doPrediction()) devuelve las ‘ys’ a partir de los valores ‘xs’ que le proporcionamos como parámetros (todo en forma de tensores). La función argMax([-1]) nos devuelve la clase que tiene mejor puntuación de las dos (la que tiene mayor probabilidad).
Luego en las otras dos funciones comparamos el resultado dado con el esperado e imprimimos por pantalla el resultado de la precisión para cada clase de salida y la matriz de confusión, que nos muestra los aciertos y errores para cada clase.
Si ejecutamos de nuevo el script (recargando la página), además de los gráficos que teníamos ahora, al terminar, se muestra esto:
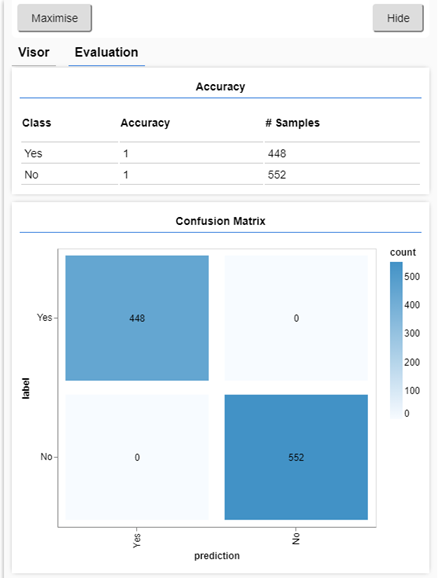
Arriba vemos la precisión por cada clase de salida y abajo la matriz de confusión (ambos elementos se corresponden con las funciones showAccuracy() y showConfusion() implementadas mediante las herramientas de tfjs-vis). Con ello comprobamos que las predicciones se ajustan al 100% con los datos reales.
Introduciendo ruido en los datos
Para finalizar, lo que haremos ahora es introducir un porcentaje de datos aleatorios. Una vez asignadas las ‘ys’ a las ‘ys’ según las normas, canviaremos aleatóriamente algunos valores para ver como se comporta la red. Pongamos por ejemplo un 10% de datos aleatorios en los que las salidas ‘ys’ no se ajustan a las normas definidas y toman valores aleatorios y veamos si aún así la red es capaz de hacer predicciones ajustadas.
Una vez recargamos el modelo la predicción que hace es la siguiente:
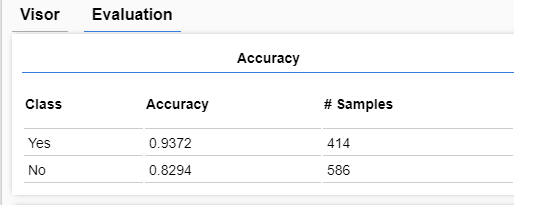
Sorprendentemente es capaz de inferir las normas que hemos implementado en los datos a pesar del ‘ruido’ que hemos introducido.
Podemos deducir que lo que hace el modelo es ignorar el ruido y aplicar las normas, de forma que el error se corresponde aproximadamente con el volumen de ruido introducido. Es decir, el modelo es capaz de inferir las normas subyacentes a pesar de que un porcentaje alto de los datos es ruido aleatório. Ésto se acerca más a un caso real en el que las relaciones pueden ser mucho mas difusas que las que hemos establecido aquí y nos muestra cómo la red puede reconocer patrones incluso si no están presentes en todos los datos.
Conclusiones y notas finales
Tensorflow es una librería completa para el desarrollo de modelos en un entorno javascript que dispone de todos los elementos que necesitamos para experimentar y desarrollar proyectos de aprendizaje computacional. En su web dispone de multitud de material de soporte, desde tutoriales hasta una API completa y bien documentada.
En éste ejemplo hemos podido comprobar que con un modelo muy sencillo es suficiente para extraer información que nos permita classificar un set de datos, en éste caso definir una clasificación binaria.
Para ello hemos diseñado un set de datos a medida, luego hemos diseñado el modelo de red neuronal que incluye las capas y sus funciones de activación, la función de pérdida y el optimizador.
Finalmente hemos entrenado el modelo y hemos hecho algunos tests.
Para el desarrollo de esta introducción nos hemos basado en los ejemplos que se proponen en la página de tensorflowjs y parte del código que mostramos está basado en el que allí se ofrece. Creemos que para alguien que empieza a moverse en éste mundo una muy buena opción aprender de quien ha diseñado la librería y conoce mejor que nadie su funcionamiento: leer sus ejemplos, seguir sus tutoriales, investigar y entender la API y finalmente lanzarse a experimentar.
Esperemos que ésta introducción os anime a experimentar y jugar con ésta herramienta y disfrutarla como hemos hecho nosotros.