NEO4J
Category : Noticias
Hoy queremos hablaros de NEO4J . Neo4j es una base de datos orientada a grafos. En contraposición a las bases de datos SQL (postgreSQL, SQLServer, etc), una base de datos orientada a grafos (BDOG) representa la información como nodos de un grafo y sus relaciones con las aristas del mismo, de manera que se pueda usar teoría de grafos para recorrer la base de datos.
En una base de datos SQL estructuramos la información en tablas. Cada tabla tiene una estructura predefinida (campos, tipos, claves primarias y foraneas, etc.). En las bases de datos orientadas a grafos la información se representa mediante nodos y aristas. Hay distintas bases de datos orientadas a grafos y cada una presenta sus peculiaridades, hoy hablaremos de NEO4j.
Este tipo de bases de datos están especialmente indicadas para ayudarnos con todo lo que tenga que ver con las relaciones. Analizar redes sociales, identificar influencers, Implementar recomendadores en función de similitudes y afinidades, detectar fraudes, etc.
NEO4J funciona de forma similar a cualquier base de datos SQL: levantamos un servidor con nuestra base de datos a la que podemos hacer consultas (por ejemplo desde el navegador, accediendo al puerto http://localhost:7474/browser/) que nos devuelven una respuesta. Además ofrece una versión de escritorio, que proporciona un entorno agradable e intuitivo para empezar a descubrir las posibilidades de éste tipo de base de datos y dispone de drivers para java, javascript, python, .Net o Go.
NEO4J tiene su propio lenguaje de consultas: Cypher. Pero antes de introducirlo echemos un vistazo a las principales diferencias entre las bbdd SQL y las orientadas a grafos. Adiconalmente, podemos usar GraphQL si estamos más familiarizado con este lenguaje.
Un caso típico: en nuestra base de datos tenemos una tabla de actores y otra de películas, un actor puede participar en una o más películas y en una película pueden participar varios actores. Para relacionarlos a ambos necesitamos una tercera tabla que contenga éstas relaciones, con sus respectivas claves foráneas. Es lo que se conoce como join table, una tabla que contiene información sobre relaciones.
En Neo4j cada actor o película son un nodo y se relacionan entre ellos mediante aristas que representan la relación. De este modo ya no hay claves foráneas ni join tables, tampoco hay tablas con columnas fijas ni tipos predefinidos. Sólo hay nodos y aristas con distintas propiedades y etiquetas.
Cypher
Es el lenguaje de consultas de Neo4j. Los elementos básicos són:
( ) -> representan nodos
[ ] -> representan relaciones
I por ejemplo:
(a ) – [ b] –> ( c) indica que el nodo ‘a’ se relaciona con el nodo ‘c’ mediante la relación ‘b’.
La versión de escritorio de Neo4j nos ofrece una terminal con la que podemos hacer consultas cypher de las que nos devuelve la respuesta de forma visual. Cuando descargamos la versión de escritorio tenemos la posibilidad de jugar con algunos sets de datos disponibles para hacer consultas durante los tutoriales introductorios que se nos muestran. Uno de ellos es un set de actores y películas. Vemos un ejemplo de consulta y su respuesta:
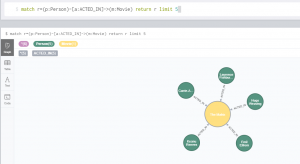
Con Neo4J y cypher no creamos modelos de nodos o relaciones en abstracto, sino que creamos directament los nodos y relaciones con los datos asociados. Así que lo ideal es predefinir nuestro modelo por ejemplo aquí. Esto es importante porque así como en las bases de datos SQL nosotros definimos el modelo (tablas, claves, tipos, etc) y luego lo rellenamos con nuestros datos, en neo4j el modelo se genera a medida que agregamos los datos.
Por ejemplo podemos hacer la siguiente consulta
CREATE (m: Movie {title:'The Matrix', released:1999, tagline:'Welcome to the Real World'})
Que crea un nodo con la etiqueta MOVIE, con propiedades tittle, released y tagline.
Podemos crear más películas pero cypher no nos dirá si las películas nuevas tienen los mismos atributos que las que ya hemos creado. Por ejemplo seria perfectamente posible hacer:
CREATE (Movie {title:'The Matrix 2' })
Es decir crear una película con sólo el nombre como atributo.
Esto nos da una idea de la flexibilidad de ésta base de datos pero también de su peligro, como hemos dicho es importante tener claro nuestro modelo de datos, puesto que Neo4j no se preocupará de que el modelo sea consistente ni de que los nodos o relaciones con una determinada etiqueta tengan todos los mismos atributos.
No pretendemos hacer de este post un tutorial de cypher, presentamos algunas consultas típicas para entender mejor lo que luego explicaremos, pero para obtener información más detallada en la página de neo4j hay la documentación de Cypher, completa y perfectamente explicada.
Ejemplos:
CREATE (TheMatrix:Movie {title:'The Matrix', released:1999, tagline:'Welcome to the Real World'})
CREATE (Keanu:Person {name:'Keanu Reeves', born:1964})
CREATE (Keanu)-[:ACTED_IN {roles:['Neo']}]->(TheMatrix) ;
Con ésta consulta creamos una película (TheMatrix), luego un actor(Keanu) y finalmente los unimos mediante una relación (:ACTED_IN) con una propiedad {roles:[‘Neo’]}. Como podemos ver el esquema es el que hemos visto antes: ( )- [ ] ->( ).
Desde luego podemos editar propiedades y etiquetas tanto de nodos como de relaciones, borrar lo que deseemos, etc.
Una vez tenemos los nodos y relaciones podemos hacer todo tipo de consultas, que básicamente responden al esquema MATCH … RETURN. En la cláusula match seleccionamos los elementos, aplicamos filtros, usamos funciones de agregación, etc y en la clausula RETURN devolvemos lo que nos interesa, ya sean nodos o relaciones concretos, campos de un nodo o relación, resultados de funciones de agregación, etc. Además se nos permite devolver esquemas enteros, por ejemplo la consulta:
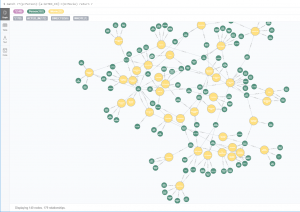
MATCH p = ( )-[ ]->( ) return p
nos devuelve todas las coincidencias con ese patrón, es decir todos los grupos de nodo-relación->nodo que tengamos en nuestra base de datos:
Un caso práctico
Para comprender mejor el potencial de éste tipo de BBDD abordaremos un caso práctico. Para ello partiremos de uno de los sets de datos que ofrece neo4j en su versión de escritorio para usar en su tutorial.
En esa base de datos tenemos los siguientes elementos, que obtenemos con esta consulta, bastante auto-explicativa:
match p = (:Customer)-[:PURCHASED]->(:Order)-[:ORDERS]->(:Product)-[:PART_OF]->(:Category) return p limit 1

Es decir, tenemos clientes que hacen pedidos, cada pedido se asocia a uno o varios productos y cada producto forma parte de una categoría. Tenemos 4 tipos de nodos (customer, order, product y category) y 3 tipos de relaciones (purchased, orders y part_of).
Uno de los casos de uso de neo4j entre muchos otros es el de construir motores de recomendación basados en las relaciones que establecemos en la base de datos. Nuestra intención en éste post es hacer esto a modo de introducción, es decir a un nivel superficial que nos ayude a ver las posibilidades de la herramienta, pero es evidente que esto se puede llevar a niveles de mayor complejidad, para los que necesitaríamos mucho más que un post.
Un primera aproximación podría ser una consulta como la siguiente:
MATCH
(c:Customer{customerID:'BOLID'})-[:PURCHASED]->(:ORDER)-[:ORDERS]->(product:Product),
(product)<-[:ORDERS]-()<-[:PURCHASED]-(:Customer)-[:PURCHASED]->()-[:ORDERS]-(product_2:Product),
(product)-[:PART_OF]-(category:Category)-[:PART_OF]-(product_2)
where product_2 <> product
return product_2, category
Vamos a desglosarla:
- Para el customer ‘BOLID’, product = todos los productos que salen en sus pedidos
- Para cada uno de esos productos, otros clientes que lo han comprado + qué otros productos han comprado.
- Definimos que cada uno de esos productos sea de la misma categoria que los que compra el cliente ‘BOLID’. Es decir, cada uno de los productos que compran los otros clientes por lo menos debe pertenecer a una de las categorias a las que pertenece alguno de los productos que compra el cliente ‘BOLID’.
Finalmente en la cláusula where eliminamos los productos que ya esté comprando el cliente.
La respuesta que obtenemos si hacemos devolvemos los productos (product_2) y las categorias es (return product_2, category):
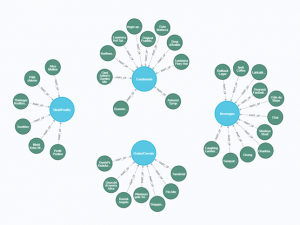
La idea es que en cada línia vamos creando variables que filatramos en las siguientes línias hasta llegar al resultado deseado.
En relación a la respuesta, también es posible hacer algo como lo siguiente:
MATCH
(c:Customer{customerID:'BOLID'})-[:PURCHASED]->(:Order)-[:ORDERS]->(product:Product),
(product)<-[:ORDERS]-()<-[:PURCHASED]-(:Customer)-[:PURCHASED]->()-[:ORDERS]-(product_2:Product),
(product)-[:PART_OF]-(category:Category)-[:PART_OF]-(product_2)
where product_2 <> product
return distinct product_2.productID
En éste caso obtenemos sólo la lista de las id de los productos:

Podemos pensar por un momento en cómo seria la consulta en SQL:
Para cada id de producto o cliente tenemos que cruzar 5 tablas:
Customers – purchased -order – orders -product
Por ejemplo para conseguir la id de los productos que compra el customer ‘bolid’:
Select p.product_id From products p Inner join orders o on o.product_id = p.product_id Inner join order ord on ord.order_id = o.order_id Inner join purchased pur on pur.order_id = ord.order_id Inner join customers c on c.customer_id = pur.customer_id Where c.customer_name = ‘BOLID’
¿Y cómo abordamos la consulta?
Primero seleccionamos estos productos, luego deberíamos buscar todos los clientes que compran esos productos.
Algo como:
Select customer_id from customers c
Inner join purchased
Inner join order
Inner join orders
Inner join products
Where product_id in (consulta anterior)
Luego deberíamos hacer otra consulta para determinar los productos que compran éstos clientes pero que no compra el cliente origina y añadirla a lo que ya tenemos. No pondremos la consulta aquí pero podemos hacernos una idea de lo rápido que crece para una pegunta relativamente sencilla y del tipo de esquema que se genera, en el que vamos acumulando subconsultas con múltiples ‘joins’.
Vamos a añadir un grado mas de complejidad a nuestra consulta. Ahora queremos averiguar los 3 clientes que más compran (de los que compran los mismos productos que el cliente ‘BOLID’) y obtener la lista de productos que compran y que no está comprando el cliente objetivo, lo podemos hacer de la siguiente manera:
MATCH
(c:Customer{customerID:'BOLID'})-[:PURCHASED]->(:Order)-[:ORDERS]->(product:Product),
(product)<-[ORDERS]-()<-[:PURCHASED]-(customer:Customer)-[:PURCHASED]->(Order)-[o:ORDERS]-(product_2:Product),
(product)-[:PART_OF]-(category:Category)-[:PART_OF]-(product_2)
where product_2 <> product
with collect(distinct product_2.productID) as recomended_products, sum(toFloat(o.unitPrice)*toFloat(o.quantity)) as qtt, customer
order by qtt desc
return customer.customerID, qtt, recomended_products
limit 3
Como vemos hemos añadido alguna línea mas:
WITH […] -> En cada relación de pedido [o:ORDERS] tenemos dos atributos, o.unitPrice y o.Quantity (precio por unidad y cantidad). Así que multiplicamos y obtenemos el valor de cada pedido. Además agrupamos por Customer y añadimos la lista de productos de éste cliente. Esto seria lo equivalente a hacer un group by, sólo que aquí es implícito. Como estamos concatenando las id de los productos con el collect() y sumando el precio de cada pedido sum(unidades * cantidad), todo lo que añadamos a continuación define el ‘group by’. En éste caso agrupamos ésta información por clientes.
Luego ordenamos según el valor de la suma y devolvemos sólo tres resulados:

Con esto tenemos los 3 clientes que mas compran productos de la misma categoria que el cliente de referencia ‘BOLID’ (y que compran al menos un producto que compra nuestro cliente de referencia). Además tenemos la lista de los productos que podríamos recomendar.
Para ir más allá deberíamos hacer más de una consulta, pero queda claro que con una consulta relativamente sencilla, corta e intuitiva podemos obtener una gran cantidad de información. Para llegar al mismo punto con SQL deberíamos construir una consulta larguísima y mucho más complicada de leer.
Éste es un ejemplo trivial a modo de introducción, para realizar operaciones mas complejas que impliquen varias consultas, procesar los datos o realizar cálculos estadísticos mas complejos una buena opción es construir un servidor más o menos complejo (en Python, Java o cualquier de los lenguajes para los que Neo4j ofrece soporte). Python nos parece una buena opción puesto que dispone de multitud de buenas librerías relacionadas con el análisis de datos (NumPy, SciPy o Panda, por ejemplo).
Servidor python con flask
A modo introductorio y para ver cómo lo podríamos hacer dejamos el siguiente ejemplo, en el que creamos un servidor básico con flask, que nos permite conectarnos a nuestra base de datos y definir un par de rutas con unas consultas muy simples que nos devuelvan el resultado en formato JSON, todo ello mediante el driver de neo4j para python.
Nosotros usamos el IDE pycharm en windows, que realiza la tarea de crear el venv por nosotros y es bastante intuitivo y cómodo. Debemos instalar las dependencias para poder importar flask y el driver de neo4j. Desde la terminal de pycharm (debemos tener instalado el gestor de paquetes pip en nuestro sistema):
pip install flask
pip install neo4j
Podemos guardar las dependencias en un archivo de texto (para no tener que perder tiempo buscando qué nos falta cada vez que empezamos un proyecto nuevo):
pip freeze > requirements.txt
Y ésto es todo lo que necesitamos. Tal como indicamos en el código, para levantar el servidor primero establecemos la variable de entorno set FLASK_APP=Main.py (suponiendo que Main.py es el archivo principal del servidor) des de la terminal. Luego ejecutamos flask run y listo.
Opcionalment podemos usar set FLASK_ENV=development que reinicia automáticamente el servidor cada vez que realizamos cambios.
Si miramos el código de nuestro servidor vemos que hay 3 partes:
Conexión: los datos de la conexión a neo4j
Queries: definimos una clase queries para luego poder hacer consultas que implementamos como métodos de la clase (hay muchas formas de hacer eso, existe una extensa documentación sobre cómo hacer las consultas y transacciones en la página de neo4j, nosotros exponemos un ejemplo básico).
Routes: definimos las rutas de acceso que nos permitirán hacer consultas a nuestro servidor. Aquí podemos implementar los métodos que deseemos (post, get, put, etc.).
La ruta /<productname> nos devolverá los productos de su misma categoría y la ruta /customer/<customerID> nos devolverá la información del cliente con esa ID, siempre en formato json.
Luego podemos consumir estos resultados con los métodos POST, GET, PUT, etc. desde dónde nos convenga (por ejemplo desde un frontend).
from flask import Flask, jsonify
from neo4j import GraphDatabase
app = Flask(__name__)
#------------------------------------------Start server ----------------------------------------------------------------
#set FLASK_APP=Main.py
#set FLASK_ENV=development -> run in development mode
#flask run
#------------------------------------------Connection-------------------------------------------------------------------
NEO_URI = "bolt://localhost:7687"
NEO4j_PSWRD = '1234'
NEO4J_USR = 'neo4j'
#------------------------------------------Queries----------------------------------------------------------------------
class Queries(object):
def __init__(self, uri, user, password):
self._driver = GraphDatabase.driver(uri, auth=(user, password))
def print_same_category_products(self, productname):
with self._driver.session() as session:
result = session.run(
'MATCH (a:Product{productName:$productname})-[:PART_OF]->(b)<--(c) RETURN c.productName,'
' c.productID , b.categoryName', productname=productname)
records = []
for record in result:
records.append({'Product': record['c.productName'], 'Product id': record['c.productID'],
'Category': record['b.categoryName']})
self._driver.session().close()
return jsonify(records)
def show_customer_profile(self, customerID):
def customer(tx):
result = tx.run("match (c:Customer{customerID:$customerID}) return c", customerID=customerID).single()
records = []
for record in result:
records.append({'Customer': record['customerID'], 'Company': record['companyName'],
'City': record['city'], 'Contact Name': record['contactName']})
return jsonify(records)
with self._driver.session() as session:
result = session.read_transaction(customer)
self._driver.session().close()
return result
#------------------------------------------Routes-----------------------------------------------------------------------
a = Queries(NEO_URI, NEO4J_USR, NEO4j_PSWRD);
@app.route('/')
def main_page():
return 'Hello to flask server for neo4j'
@app.route('/<productname>')
def categories_page(productname):
return (a.print_same_category_products(productname))
@app.route('/customer/<customerID>')
def customer_profile(customerID):
return a.show_customer_profile(customerID)
Si accedemos a la ruta: http://127.0.0.1:5000/Chang
obtenemos lo siguiente:
[
{
"Category": "Beverages",
"Product": "Sasquatch Ale",
"Product id": "34"
},
{
"Category": "Beverages",
"Product": "Outback Lager",
"Product id": "70"
}
[...etc.]
]
Para ampliar éste tema recomendamos el siguiente post.
EDICIÓN: Algoritmos de búsqueda
Una de las ventajas de neo4j que anunciábamos al inicio de éste post és que nuestros datos están organizados en forma de grafos y ésto nos permite tratar-los según la teoria de grafos. Neo4j dispone de algunos sets de algoritmos que nos pueden ser muy útiles para determinar propiedades de nuestros datos que pueden no ser visibles a simple vista. Como ejemplo presentamos el algoritmo de búsqueda del camino más corto, que puede sernos útil en distintos contextos.
El set de datos
Nuestro set de datos es el siguiente:
https://www.kaggle.com/open-flights/flight-route-database#routes.csv
Se trata de una relación de aeropuertos y compañias, que contiene 59036 rutas entre 3209 aeropuertos operadas por 531 compañías aéreas.
Para nuestro ejemplo lo que nos interesa es definir el modelo siguiente:
(:airline)-[:fly-to]->(airport)
(:airline)-[:fly-from]->(airport)
Para empezar, hemos descargado el set de datos en formato csv y lo hemos guardado en:
[…]\Neo4J\neo4jDatabases\NUESTRA_BASE_DE_DATOS\installation-3.5.5\import\set_de_datos.csv
//Cremos los 'constraint' para asegurarnos de que no hay aerolínias ni aeropuertos repetidos
create constraint on (a:Airline) assert a.airlineID is unique;
create constraint on (b:Airport) assert b.airportID is unique;
//Importamos las aerolínias
using periodic commit
LOAD CSV WITH HEADERS FROM 'file:///routes.csv' as row
with row
merge (airline:Airline{airlineID:row.`airline ID`})
set airline.airlineName = row.airline;
//Importamos los aeropuertos (repasamos la lista de origen y destino, cuidado con los nombres de las columnas y los valores nulos)
using periodic commit
LOAD CSV WITH HEADERS FROM 'file:///routes.csv' as row
with row
where row.`source airport id` is not null
merge (a:Airport{airportID:row.`source airport id`})
on create set a.airportName = row.`source airport`;
using periodic commit
LOAD CSV WITH HEADERS FROM 'file:///routes.csv' as row
with row
where row.`source_airport_id` is not null
merge (a:Airport{airportID:row.`destination airport id`})
on create set a.airportName = row.`destination airport`;
//Creamos las relaciones:
LOAD CSV WITH HEADERS FROM 'file:///routes.csv' as row
with row
where row.`source_airport_id` is not null
match (a:Airline{airlineID:row.`airline ID`})
match (ap:Airport{airportID:row.`source_airport_id`})
merge(a)-[:FLY_FROM]->(ap);
LOAD CSV WITH HEADERS FROM 'file:///routes.csv' as row
with row
where row.`source_airport_id` is not null
match (a:Airline{airlineID:row.`airline ID`})
match (ap:Airport{airportID:row.`destination_airport_id`})
merge(a)-[:FLY_TO]->(ap);
Una vez tenemos esto ya estamos en condiciones de usar el algoritmo de búsqueda para encontrar el camino más corto entre aeropuertos. En éste caso como las relaciones no tiene peso (es decir no hay un coste asociado a cada ruta), el camino más corto calcula el mínimo número de pasos que tenemos que seguir para ir de un aeropuerto a otro, o sea el mínimo de aeropuertos en los que deberíamos hacer escala.
Primero de todo lo que debemos hacer es habilitar el set de algoritmos, ésto se puede hacer desde neo4j desktop, accediendo a las propiedades de nuestra base de datos y activando el set ‘graph algorithms’:
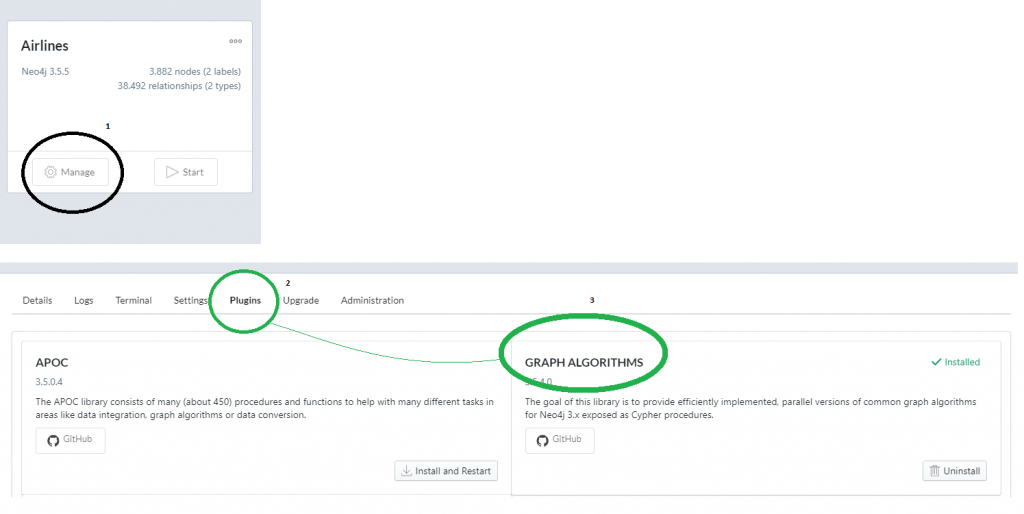
Una vez hecho esto, realizamos la siguiente consulta:
MATCH (start:Airport{airportName:'ACE'}), (end:Airport{airportName:"AEY"})
CALL algo.shortestPath.stream(start, end, "cost")
YIELD nodeId, cost
MATCH (other:Airport) WHERE id(other) = nodeId
RETURN other.airportName AS name, cost
En la que a través de la llamada CALL algo.shortestPath.stream(start, end, «cost») buscamos la ruta más corta entre los aeropuertos ACE y AEY (Lanzarote e Islandia), mostrando el siguiente resultado, en el que se ve que la ruta mas corta entre ACE y AEY pasa por KEF y KUS.
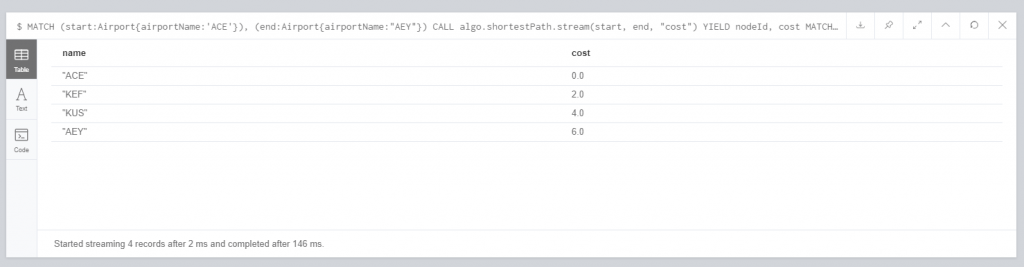
Finalmente comentar que hemos ido muy deprisa, hay muchos pasos que pedirían un post entero, por ejemplo importar desde csv, la operación merge o el propio algoritmo, pero nuestra intención es introducir el tema y animar a investigar las posibilidades que ofrece. Si os ha parecido interesante recomendamos como siempre consultar la documentación oficial, completa y detallada.