Tendencias BI 2019
Category : Noticias
El mercado de las soluciones analíticas está cambiando y bastante deprisa en los últimos años. Antes había unas cuantas herramientas que se repartían el mercado, cada una en su segmento. Cognos, Business Objects y Microstrategy para las grandes empresas. Qlik y Tableau para las medianas y Pentaho ( ahora Hitachi Vantara), Jasper y SpagoBI (ahora Knowgate) en el àmbito Open Source.
Pero ha pasado que, las soluciones Open Source, se han comido parte del mercado. Por lo que, las soluciones de pago han ido abaratando costes progresivamente. Además de la irrupción del cloud. Todo esto ha hecho que casi todas las herramientas hayan sacado una versión cloud mucho más barata y mantenible. Así cómo ediciones personales gratuitas.
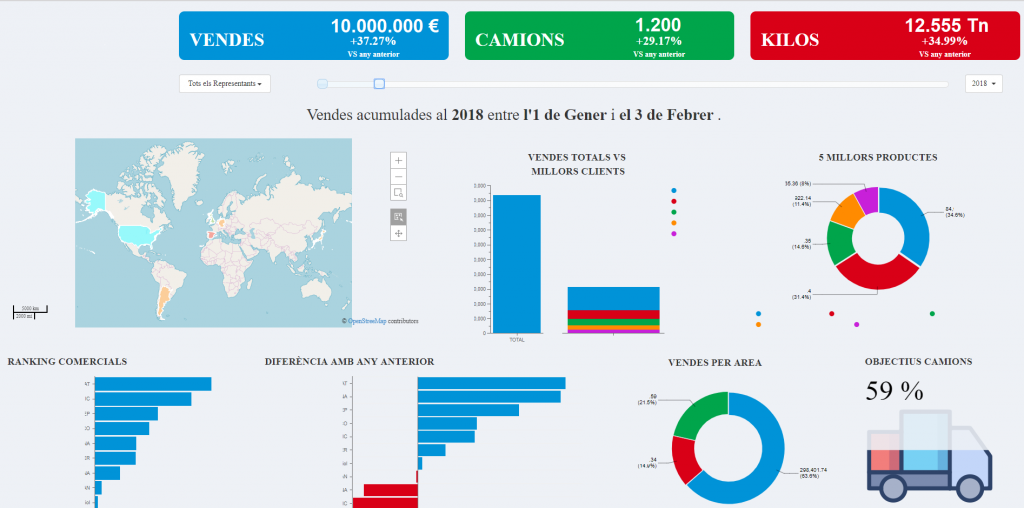
 Es un placer anunciar que hemos subido al marketplace de pentaho una nueva versión de WAQE. Es la primera revisión de la primera versión que consideramos estable y hemos pulido algunos bugs y añadido algunas funcionalidades nuevas. Entre las que destacan filtros personalizados o aumentar el volumen de datos a exportar.
Es un placer anunciar que hemos subido al marketplace de pentaho una nueva versión de WAQE. Es la primera revisión de la primera versión que consideramos estable y hemos pulido algunos bugs y añadido algunas funcionalidades nuevas. Entre las que destacan filtros personalizados o aumentar el volumen de datos a exportar.